Thomas Berger, CTO de La Centrale : « notre carburant n°1, c'est la donnée »

Le directeur technique détaille l'organisation de la donnée au sein de la marketplace de véhicules d'occasion, selon les principes du Data Mesh. Et souligne comment la GenAI s'immisce un peu partout dans ses opérations.
PublicitéLa Centrale est avant tout connue pour sa marketplace spécialisée dans les véhicules d'occasion, mais le groupe possède aussi un site éditorial (Caradisiac) et un site de ventes de véhicules neufs à prix réduit (Promoneuve). La société, qui affiche 55 ans d'existence (le groupe éditait au départ un journal de petites annonces), compte environ 250 personnes, dont une centaine sur les volets technologies et produits. L'essentiel de cette équipe, organisée en feature teams, est constitué de profils internes, parmi lesquels 70 personnes environ dans le développement, le devops et le test ou la qualité.
« Nous avions nos datacenters en propre dans notre bâtiment jusqu'en 2014. Et nous avons connu une inondation, ce qui a provoqué une prise de conscience. Ce qui était devenu clef pour nous n'était plus l'imprimerie, mais nos données », raconte le CTO, Thomas Berger. La migration vers le cloud d'AWS a alors été vue sous le prisme de la pérennité de la data. Une histoire qui s'est poursuivie au gré des évolutions technologiques.
Comment est organisée la data, qui porte le coeur de votre activité ?
Thomas Berger : Nous avons mis en place une organisation en data mesh depuis environ deux ans. Le coeur du métier de La Centrale consiste à faire de la collecte, de la transformation et de l'analyse de données, car nous ne vendons pas de voitures. Notre métier revient à mettre en relation un acheteur et un vendeur et nous allons utiliser la data pour améliorer cette transformation. Par exemple, nous attribuons aux annonces ce que nous appelons des badges, qui définissent si un véhicule est ou non une bonne affaire. En fonction de toutes les annonces que nous recevons - 600 000 par an environ -, ces badges évaluent le niveau de prix par rapport à l'histoire spécifique de chaque véhicule.
Nous avons donc un pôle de données autour des véhicules, issues des annonces que nous allons analyser, mais aussi que nous allons enrichir. Notamment sur la base de notre référentiel, pour corriger les erreurs de saisie et arriver à une donnée de qualité. L'objectif est de parvenir à la description la plus complète du véhicule, ce qui représente jusqu'à 300 à 400 points de données différents. Mais nous avons aussi un pôle de données sur les professionnels qui vendent des voitures d'occasion, afin par exemple de récupérer des avis de consommateurs sur la qualité de leurs prestations. L'acquisition d'une voiture est un achat important dans la vie des Français, qui veulent connaître le degré de confiance qu'ils peuvent accorder à un professionnel. Cela permet aussi de mieux accompagner ces professionnels, un sujet clef pour nous, car 80% de nos annonces proviennent de ces acteurs. Enfin, nous avons un pôle de données lié à l'utilisation de notre plateforme, qui génère environ 35 millions de visites par mois. Ce qui nous permet d'améliorer notre marketplace et de lancer de nouveaux produits. Nous avons par exemple créé un produit de tendances de marché, en analysant les actions qu'enregistre la plateforme.
PublicitéAvez-vous aussi recours à de la donnée externe ?
Tous les ans, nous voyons passer 6 millions de plaques d'immatriculation, soit 15% du parc de véhicules en France. Nous avons donc déjà beaucoup de data. Mais nous allons effectivement chercher des données de constructeurs, pour bien comprendre leurs options et les particularités qu'elles présentent afin aboutir à un catalogue exhaustif de véhicules.
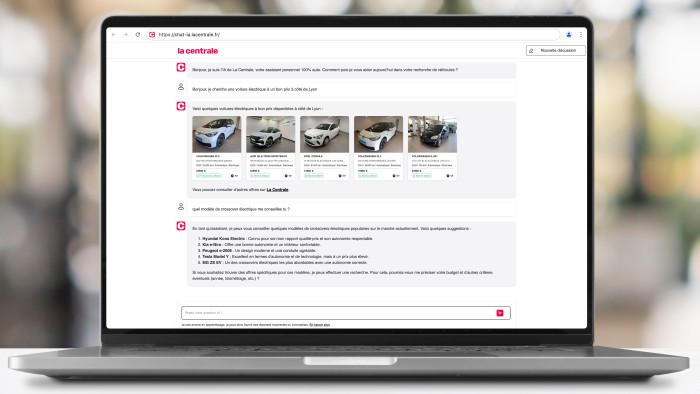
La Centrale a déployé un assistant à base de GenAI pour guider les utilisateurs de sa plateforme dans la recherche d'un véhicule d'occasion convenant à leurs besoins. (Photo : D.R.)
Pourquoi avoir choisi le modèle data mesh pour exploiter ce triple patrimoine de données ?
Nous partions d'un gros datalake. Or, le premier problème de cette architecture réside dans l'organisation qui l'accompagne. Comme nous sommes une entreprise tech et data, tout le monde dans l'entreprise a besoin d'accéder à la donnée, en étant à la fois producteur et consommateur de celle-ci. Dans un modèle datalake, cela suppose de mettre en oeuvre une importante équipe data. Mais, aussi imposante soit-elle, celle-ci ne peut pas connaître toutes les complexités des différents métiers.
Pour éviter une croissance disproportionnée de l'équipe data, nous avons pris la décision de décentraliser, pour responsabiliser chaque producteur, tout en lui offrant la possibilité de croiser ses données avec d'autres pour aller plus loin dans l'analyse. Pour garantir le niveau de qualité de la donnée que nous souhaitions, nous avons automatisé les contrôles au travers de nombreux outils, pour vérifier la complétude, l'évolution dans le temps de la data, etc. Y seront associés des critères de suivi et des alarmes, comme sur n'importe quel produit. La qualité de la donnée passe aussi par un langage commun, via notre data catalog qui définit tous les termes métiers.
Comment cela se traduit-il dans l'organisation ?
Dans les feature teams, nous avons défini le rôle de data owner, qui est responsable de la production de la donnée, de sa qualité et de sa disponibilité dans la plateforme. Les développeurs de produits data sont, eux, en charge de réutiliser les outils qui ont été créés pour produire, stocker et partager la donnée. Subsiste, en complément, une petite équipe pour la plateforme de données, dont l'objectif est de construire et de faire évoluer les outils.
Comment l'IA s'intègre-t-elle dans votre stratégie ?
Nous utilisons l'IA depuis 7 ou 8 ans, avec plusieurs produits en production basés sur du machine learning. C'est par exemple le cas avec la côte de l'occasion ou dans des dispositifs antifraude, passant par la détection de schémas de discussion suspects. Nous testons d'ailleurs la GenAI sur ces usages. C'est également du machine learning qui est exploité pour choisir la photo de présentation du véhicule dans notre moteur de recherche, où nous privilégions les clichés de trois quarts face. Comme nous recevons 4 millions de photos par mois, c'est un algorithme qui les tague automatiquement, pour sélectionner celle qui sera mise en avant.
Et si celle-ci est absente ? Avez-vous testé la GenAI pour créer cette photo manquante ?
Nous avons effectivement effectué quelques tests avec l'IA générative sur ce terrain, mais ce n'est pas encore concluant : une voiture d'occasion reste un produit unique. Plus globalement, nous avons commencé à expérimenter l'IA générative depuis un an, avec de premiers produits en production depuis juin dernier. Le premier cas d'usage consiste à accompagner les utilisateurs dans la recherche du véhicule qui leur conviennent, 67% des Français trouvant ce processus complexe. Nous avons développé un assistant, auquel nous avons appris tous les critères clefs concernant les véhicules, soit des centaines. Cet assistant est capable d'interagir avec notre stock, pour aller chercher la bonne annonce à partir de l'interrogation en langage naturel d'un visiteur. Techniquement, il s'agit d'appels de fonctions couplés à différents niveaux d'ingénierie de prompt. Nous allons y ajouter du RAG, pour greffer sur les avis journalistiques de Caradisiac, afin d'apporter une dimension de conseil aux internautes.
A quelles problématiques vous êtes-vous heurté dans ces développements ?
D'abord, à cette époque, chaque requête coûtait très cher. Un des premiers axes de travail a donc été de réduire la facture, en utilisant différents modèles. Nous avons réussi à diviser par 100 le coût d'une requête. Désormais, nous sommes également en mesure de changer de modèle en deux à trois semaines, grâce notamment à la qualité de nos données et de nos API. Nous essayons de nous baser sur le plus petit modèle possible et de rester souples. Nous avons désormais atteint un niveau où le coût n'est plus un obstacle pour nos usages.
L'autre question que nous nous sommes rapidement posée, c'est comment évaluer des modèles non déterministes pour identifier celui qui est le plus adapté à nos cas d'usage. Nous avons donc bâti un catalogue de prompts et une automatisation des tests de la qualité des réponses, via une évaluation par un LMM. Nous avons aussi utilisé les compétences des journalistes de Caradisiac pour évaluer les sorties des modèles. Au final, nous avons développé, pour notre premier cas d'usage, une plateforme de GenAI, au-dessus de Bedrock, embarquant tout l'outillage nécessaire, nous permettant ainsi de sortir une nouvelle idée en quelques semaines. C'est ce mécanisme que nous venons d'exploiter pour un nouveau cas d'usage, l'automatisation de la rédaction d'une annonce pour les particuliers, à partir des caractéristiques techniques du véhicule. Cette fonction, sortie début avril, est déjà exploitée par un tiers des utilisateurs.

« Plus nous fournissons de données aux professionnels, plus ils s'y noient. Nous voulons utiliser l'IA générative pour transformer ces données en langage naturel afin de leur délivrer des conseils. »
L'assistant que vous avez déployé en juin dernier permet-il d'améliorer le taux de transformation ?
Quelqu'un qui passe par l'assistant a deux fois plus chances de contacter un professionnel que quelqu'un qui se cantonne à la recherche classique. Même si on reste à ce stade sur de petits volumes à l'échelle de notre audience, soit entre 10 000 et 20 000 conversations par mois. Ces conversations nous permettent aussi de mieux comprendre les attentes des internautes. Là où, auparavant, nous nous contentions d'analyser les actions sur le site, soit un proxy des intentions réelles des utilisateurs, nous avons désormais un accès direct à leurs questions, formulées en langage naturel. Nous utilisons donc un autre modèle d'IA pour interpréter ces conversations et en extraire des tendances et des statistiques.
Quelles sont les prochaines étapes de cette stratégie ?
Nous voulons identifier tous les endroits où la genAI va pouvoir aider nos clients, particuliers ou professionnels. Nous avons bien avancé sur les particuliers et voulons maintenant nous concentrer sur les professionnels, qui représentent 95% de notre chiffre d'affaires. Nous leur fournissons déjà, via une suite d'outils, beaucoup de data, sur leur stock, sur leur positionnement par rapport à leurs concurrents, sur les tendances, etc. Mais plus nous leur fournissons de données, plus ils s'y noient. Leur métier n'est pas d'être des analystes data. Nous voulons utiliser l'IA générative pour transformer ces données en langage naturel afin de leur délivrer des conseils leur permettant d'augmenter le taux de rotation de leur stock ou d'optimiser leurs marges par exemple. Au total, nous avons des dizaines de projets de GenAI à l'agenda pour cette année.
En interne, quels usages faites-vous de l'IA générative ?
Nous avons déployé un chat sécurisé interne, toujours sur Bedrock, pour l'ensemble du personnel. Il est déjà exploité par 70% des employés. Sur les processus et la productivité eux-mêmes, nous déployons aussi des assistants pour la programmation. Via l'intégration avec MCP (model context protocol), on peut aller jusqu'à l'automatisation de tâches, comme des corrections automatiques de composants après le déclenchement d'une alarme. Nous travaillons sur ce sujet, qui peut avoir un impact important dans une entreprise comme la nôtre qui publie entre 5000 et 6000 commits par an.
Quel est le candidat le plus évident pour ce type de scénarios d'automatisation sur votre architecture ?
Probablement le passage à l'échelle lors des pics de trafic. Notre trafic est assez stable, mais, parfois, des bots parviennent à créer des à-coups. Tout l'enjeu est alors d'adapter l'infrastructure, sans aller trop loin pour ne pas engendrer des surcoûts trop importants. Les montées de version logicielle ou la gestion des conflits ou des dépendances de librairies sont d'autres candidats intéressants pour la mise en place de ces schémas d'automatisation.
Article rédigé par

Reynald Fléchaux, Rédacteur en chef CIO
Suivez l'auteur sur Twitter
Commentaire
INFORMATION
Vous devez être connecté à votre compte CIO pour poster un commentaire.
Cliquez ici pour vous connecter
Pas encore inscrit ? s'inscrire